
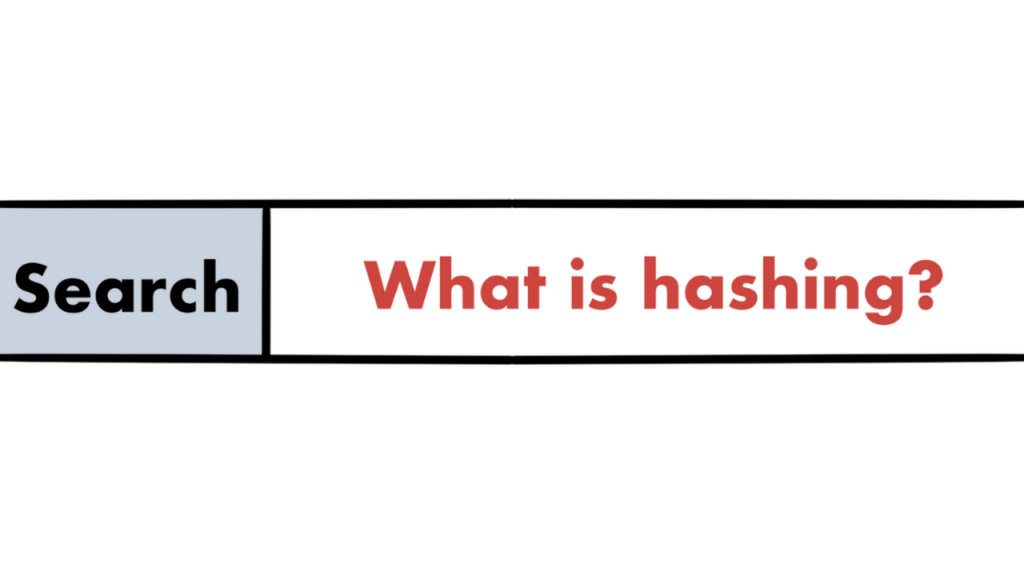
A hash function takes in an input string of any length and gives an output hash of a fixed length. Upon hashing, you get a string of pseudo random alphabets and numbers as an output which will look like this -> 242485AB6BFD3502BCB3442EA2E211687B8E4D89.
Hash functions are the cornerstone of the blockchain’s architecture. So, if you want to understand the blockchain and cryptocurrencies better, you must have complete clarity on what hashing and is and what it can potentially do. We will also look into various sidenotes such as hashing vs encryption to help us understand the main differences between them.
What are hashing properties?
Let’s look at some of the unique properties and features of these hash functions.
#1 Deterministic
First and foremost, cryptographic hash functions are deterministic in nature. This means that no matter how many times you parse one input through a specific hash function, you will always get the same output. This is extremely important for multiple reasons, the least of it being operational accuracy.
#2 Faster Operations
Hash functions need to be very fast and efficient. The hash calculation has to be as fast as possible. Otherwise, it will be impossible to use them in real-time calculation scenarios.
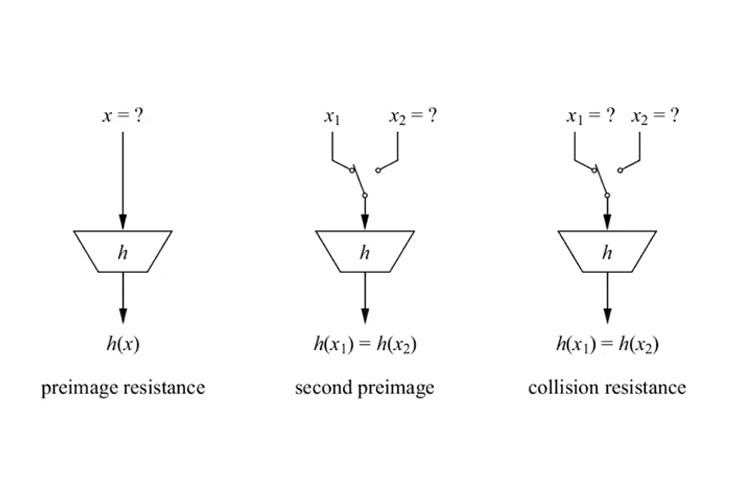
#3 Pre-image resistance
First, let’s understand what pre-image resistance means. If H(A) is the hash and H() is the hash function, A will be the pre-image. Simply put, its the value that gets hashed by the hash function. So, the pre-image resistance states that if given H(A), it is infeasible to figure out the value of A.
So, why do we say infeasible rather than impossible?
The reason is that it is not impossible to find the pre-image of a hash. All that it requires is a brute-force attack and a whole lot of time and patience to crack a hash. But the real question is, how long will you need to break this hash? Suppose you are using a 128-bit hash, and you want to figure out what the pre-image could be. In this situation, there are three possible scenarios that we are dealing with:
- Best case scenario: You somehow luck into the correct answer on your first try. However, this is practically impossible.
- Worst case scenario: You finally get the answer after 2^128-1 attempts. In other words, you find it at the very end of all the data.
- Somewhere in the middle: You get your answer after (2^128)/2 = 2^127 = 1.7 X 10^38 times.
Either way, it’s a huge number, and it will take a long time and a vast amount of calculations to even attempt to break it. In other words, it’s simply not worth it.
#4 Snowball Effect
To understand this property, let’s look at a simple example. Look at the following table. Note, we are using a SHA-256 hashing algorithm.

Do you see what happened here? We just changed the alphabet of the input from the upper case to lower case, which triggered a huge change in the output hash. This is a valuable property, so keep it in mind for the future.
#5: Collision Resistant
Given two hashes H(A) and H(B), with pre-images A and B, H(A) can’t be equal to H(B). Basically, each hash, for the most part, is unique. The keyword here is “for the most part.” To understand what we mean, let’s look into the birthday paradox.

If you go out on the streets, then the chances are very low that you’ll have the same birthday as some random stranger you encounter. However, if you gather up 20-30 people in one room, there is as much as a 50-50 chance for two people to share the same birthday.
Why does this happen?
Imagine that you have N different possibilities of an event happening. In this case, you need a square root of N to have a 50% chance of a collision. When it comes to birthdays, there are 365 distinct possibilities of that event happening. Upon square rooting that, we get sqrt(365) = ~23. This is why, in a room with 20-30 people, there is a chance of a collision.
How is this applicable in hashing? Well…if you have a 128-bit hash with 2^128 possibilities. By square rooting, we have 2^64 options. What this means is that we have a collision instance at the 2^64th instance. By this logic, no hash function in the world is collision-free.
#6: Puzzle Friendly
The final property is puzzle-friendliness. For every output Y, if we choose a random variable “k” from a high min-entropy distribution, it is infeasible to find a random number x, such that:
H(k|x) = Y.
Let’s look at the terms being described here:
- High min-entropy distribution: A highly-varied distribution that is known as having a high min-entropy. Choosing a number between 1 and 3 is a low min-entropy distribution while selecting a number between 1 and million is a high min-entropy.
- k|x: The “|” is a sign for concatenation. Concatenation is a term used to describe the addition of two strings. So, concatenating “HARRY” and “POTTER” gives you “HARRY POTTER.”
Hashing in computer science
In computer science, there are are two very well-known data structures that play a pivotal role in blockchain architectures:
- Pointers
- Linked Lists
Pointers
In traditional programming, pointers are variables that store the address of another variable. These variables are pointing towards another variable. A hash pointer is a special class of pointers that contain the hash of the value of the variable that it’s pointing towards. This is one of the most well-known cases of hashing in computer science.
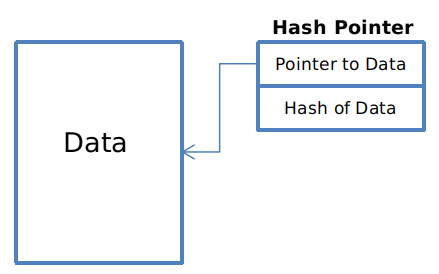
Linked Lists
This is what a linked list looks like:
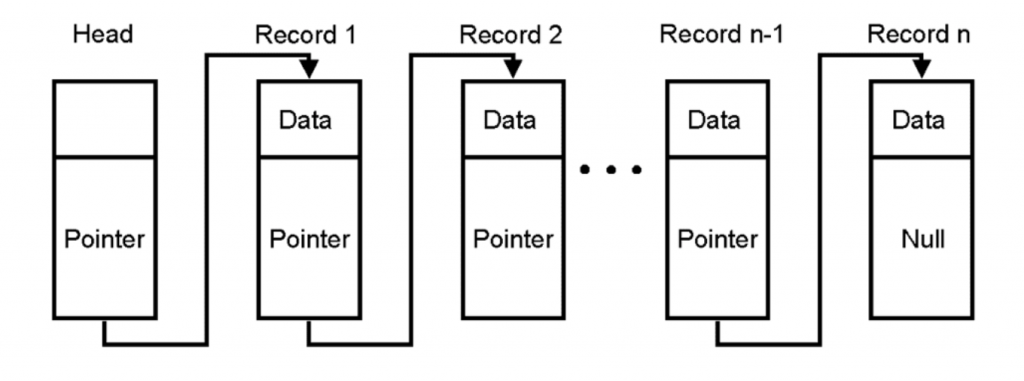
A linked list is a sequence of blocks, each of which contains some data. A pointer links the blocks to each other and contains the address of the next block in it. You are probably wondering that this is all well and good, however, this isn’t an example of hashing in computer science, right?
Well, let’s take things to a whole other level.
What if, instead of a pointer, we use a hash pointer that contains the hash of the preceding block?
Does it sound familiar?
Well, it should, because that’s what a blockchain technically is.
Hashing vs Encryption
Before we go any further, there is another concept that should be made clear when it comes to hashing in computer science – hashing vs encryption. While both are techniques used in cryptography, they are still vastly different.

- Encryption: Encryption and decryption are two parts of both asymmetric and symmetric cryptography. Encryption is the process wherein the file text gets converted to ciphertext. The only way to decode the ciphertext is to use the corresponding decryption key.
- Hashing: Hashing is not a two-way process. The idea is just to convert your input data into an output hash.
We hope that this has clarified the whole encryption vs hashing debate for you. Alright, let’s move on.
Hashing in blockchain structures
The following is a simplified version of the bitcoin blockchain.
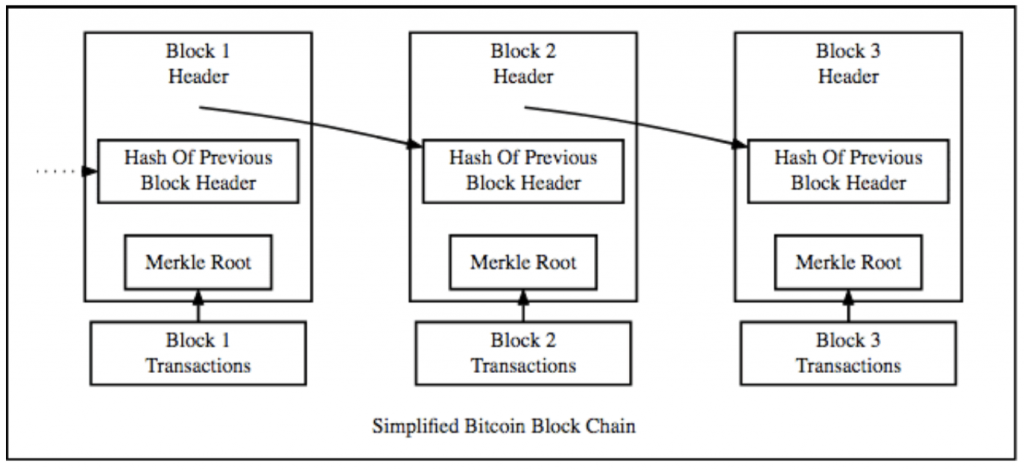
As you can see, it kind of looks like a simple linked list with hash pointers. Now you are probably wondering, why are we even using a hash pointer in the first place? Well, this is how we impart one of the blockchain’s most important features – immutability.
Immutability means that once you input data into the blockchain, it should be completely non-tamperable. There is nothing that you can do to remove the data. To understand how this works, keep in mind the “snowball effect” property of hash functions. Now imagine that someone has attempted to remove data from block #2 of our blockchain.
- Changing the data in block 2 drastically changes the hash stored in block 3 (snowball).
- Changing the hash stored in block 3 changes the overall data stored inside it.
- This changes the overall hash of block 3, which is stored in block 4.
This creates a whole chain reaction, which should theoretically change the whole blockchain, but since that’s an impossibility, the blockchain becomes immutable.
What hashing algorithm does bitcoin use to hash blocks?
Now that we have a basic understanding of how cryptographic hashing works let’s answer the million-dollar question – what hashing algorithm does bitcoin use to hash blocks? In previous sections, we have repeatedly used this hashing algorithm, called “SHA-256.” Over here, SHA stands for Secure Hashing Algorithms.
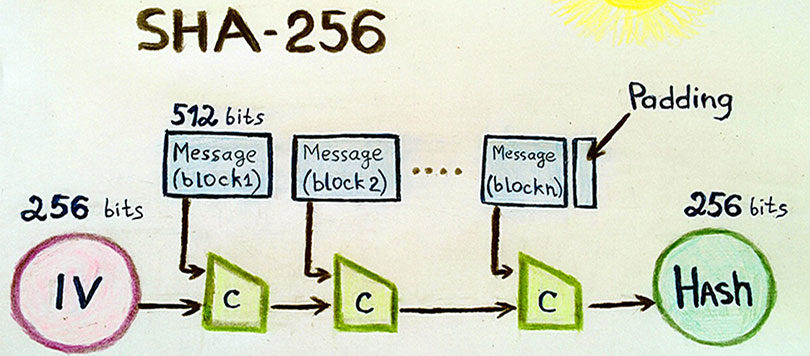
Secure Hashing Algorithms (SHA)
SHA is a family of cryptographic hash algorithms that have been published by NIST or the National Institute of Standards and Technology. The SHA is a U.S. Federal Information Processing Standard (FIPS). The different types of SHA algorithms are as follows:
- SHA-0: Originally published in 1993 and was a 160-bit hash function. However, it was removed as soon as researchers discovered a significant flaw in the system and replaced it with SHA-1.
- SHA-1 : This version was designed by the National Security Agency (NSA) to be part of the Digital Signature Algorithm. This is also a 160-bit hash function. However, it also had specific cryptographic weaknesses.
- SHA-2: NSA created this by using the Merkle-Damgard paradigm. There are two SHA-2 hash functions – SHA-256 and SHA-512. Bitcoin uses SHA-256.
- SHA-3: This was created in 2012 during a public competition by non-NSA designers. While it has the same lengths as SMA -2, but its internal structure differs from the rest of the SHA algorithms.
Hashing in Bitcoin operations
Hashing is primarily used in two Bitcoin operations:
- Mining: A resource-intensive process wherein miners solve cryptographically hard puzzles to find an appropriate block to add to the chain. This process is called proof-of-work.
- Creation of addresses: A combination of SHA-256 and RIPEMD-160 hash algorithms are used to convert your public key to a public address. Changing the public key to a public address makes it more secure and efficient.
#1 Hashing in mining
Specialized Bitcoin nodes called “miners” continuously mine new Bitcoin blocks and ensure that the blockchain keeps on growing in length. To understand POW mining, we need to understand a metric called “difficulty.” Remember, there are only 21 million bitcoins that will ever be mined. If the miners aren’t restricted, nothing will stop them from thoroughly mining out all the coins in existence.

Along with this, you should also keep in mind that Bitcoin must have a consistent block time of 10 mins. If this block time isn’t maintained, it results in:
- More collisions, since it will lead to the generation of more hashes.
- Since the miners will be mining more frequently, it will inevitably lead to more orphaned blocks, aka, blocks that have been properly mined but don’t carry any transactions inside them.
To honor these restrictions, the Bitcoin protocol has a metric called “difficulty.” As is pretty self-evident, the difficulty metric defines how cryptographically hard the puzzle that the miners will need to solve has to be. The difficulty target is a 64-character string and begins with a bunch of zeroes when it comes to bitcoins. Depending on the ease of mining, the difficulty level changes every 2016th block.
How does Bitcoin mining work
- Miners pick up random transactions that are queued up in the mempool and put them in a block.
- The contents of the block is hashed.
- A nonce or a random hexadecimal string is then added to the front of the hash.
- The new composite string gets hashed again and compared to the difficulty metric.
- If the new hash is valued below the difficulty level, then the mining is a success and the miner gets to add the block to the main bhain and receive a reward.
- However, if it doesn’t satisfy the parameters, the miners need to change the nonce and continue the process till they are successful.
Hash property applicable in mining
A fascinating hash property that we saw during our discussion above is puzzle-friendliness. To give you a quick recap, for every output “Y,” it is infeasible to find an input “x” such that H(k|x) = Y. In this case:
- Y is the final hash, which needs to be less than the target difficulty.
- k is the nonce chosen by the miners.
- x is the hash of the contents of the current block.
The design principles of the whole mining process is as follows:
- The puzzle-solving part is challenging.
- However, checking if the solution is correct by combining the nonce with the block hash is easy (as per the “Faster Operations” property).
What is hash rate?
Another term that gets tossed around a lot when it comes to Bitcoin and POW cryptocurrencies, in general, is “hash rate.” It is a metric that calculates the speed with which hash operations are taking place within the network.

- A high hash rate is indicative of the network that has faster hashing operations. Hence this network is faster and more secure.
- A low hash rate indicates a network that has slower hash operations. These networks are comparatively slower and less secure.
#2 Hashing in public address creations
The second major hashing use case in cryptocurrencies is the creation of public addresses. So, how do you convert your public key to public addresses?
- The public key that’s corresponding to your private key is first generated via Elliptical Curve Cryptography (ECC) multiplication.
- The public key first gets parsed through SHA-256.
- The hash then gets passed through RIPEMD-160 to generate HASH_1 (hypothetical name).
- HASH_1 then gets parsed through SHA-256. The first seven digits of this new hash becomes HASH_2.
- The HASH_1 and HASH_2 get combined to form the public address.
Conclusion: What is Hashing?
Hashing is one of the components that form the heart and soul of the cryptocurrencies and blockchain technology. We hope that this guide was able to clearly demonstrate to you what is hashing. Plus, we also looked into what hashing algorithm does bitcoin use to hash blocks. If you are passionate about this space, then having a general idea of how cryptographic hash functions work is an absolute necessity.
Speaking of which, if you are genuinely passionate about this space and want to forge your career here, then come on over! Enroll for one of our world-famous blockchain education courses at Ivan on Tech Academy. The courses have been created by industry experts and our very own in-house trainers.




